
DeeR-VLA团队 投稿91porn y
量子位 | 公众号 QbitAI
盘算推算、存储顿然高,机器东说念主使用多模态模子的碎裂被处治了!
来自清华大学的盘问者们遐想了DeeR-VLA框架,一种适用于VLA的“动态推理”框架,能将LLM部分的关系盘算推算、内存支拨平均缩短4-6倍。
情色社区(VLA:视觉-话语-动作模子,代表一类用于处理多模态输入的模子)

苟简来说,DeeR-VLA就像东说念主的有筹画系统:苟简任务快速念念考,复杂任务仔细念念考。通过多出口架构,模子在充足盘算推算后即可提前“刹车”,幸免蹧蹋算力。
在CALVIN机器东说念主操作基准测试中,DeeR-VLA已毕了诳言语模子(LLM)盘算推算资本减少5.2-6.5倍,GPU内存减少2-6倍,同期保持了性能不受影响。

大模子存在冗余性
连年来,多模态诳言语模子(MLLM)让机器东说念主具备了前所未有的贯通与引申智商。通过话语教唆和视觉信息的结合,机器东说念主不错完成复杂任务,比如“捏起蓝色物体并放到桌上”。
一些前沿模子,如RT-2,致使不错泛化到新任务或新物体。关联词,要让这些遒劲的模子走进实质场景,还有通盘穷困需要处治——MLLM天然机灵,但也“馋嘴”。
每次推理动辄调用数十亿参数,顿然高大的盘算推算资源。
这关于镶嵌式机器东说念主平台来说是致命的——GPU内存不及、盘算推算期间长、电板续航不够,平直让“通用机器东说念主”的生机停步于实践室。
关联词实质上,在机器东说念主截至范围,好多实质利用场景并莫得咱们联想的那么复杂。
论文作家通过不雅察发现,绝大无数任求实质上不错通过较小的模子就能完成,独一在濒临少数复杂场景时,才需要调用完好的大型多模态模子。
以Calvin数据集为例的实践收尾便充分体现了这少量:当使用24层的OpenFlamingo动作基座模子时,比拟于6层的模子,任务完成率仅提高了3.2%,但盘算推算资本却加多了整整4倍。
这无疑突显了现存的多模态大模子对大部分苟简机器东说念主任务的冗余性。

这一发现激勉了对现存模子遐想的深远念念考:
为什么在大无数苟简任务中还要使用高盘算推算资源的复杂模子?
在很厚情况下91porn y,使用更大的模子不仅莫得带来彰着的性能普及,少女野外调教反而蹧蹋了矜重的盘算推算资源。
作家觉得,若何凭证任务的复杂性动态调整模子的范畴,智力在不罢休性能的情况下,最大化盘算推算后果,成为了普及机器东说念主智能的要道。

DeeR-VLA的遐想
DeeR-VLA框架的中枢在于其生动的动态推理机制,大约凭证任务复杂度智能调遣LLM的盘算推算深度。
这意味着,DeeR-VLA大约在不同场景中激活苟且范畴的模子。
为了已毕这一筹画,DeeR-VLA引入了多出口架构,该架构能在多模态诳言语模子中按需聘任性激活不同的层级。
以下是其要道本事组件:
多出口MLLM结构: DeeR-VLA通过在MLLM中引入多出口架构,将模子区别为多个阶段,每个阶段齐不错输出中间收尾。一朝任务复杂度达到某个出口的需求,模子就会提前罢手盘算推算,幸免激活更多层级。特征池化面容: 每个出口的中间特征通过特征池化本事进行压缩,索要出最中枢的信息。这种面容确保即便在早期退出,模子也能生成适用于后续动作展望的高质料特征。动作展望头遐想: 在每个出口后,模子通过轻量级的动作展望头,将特征障碍为机器东说念主具体的引申动作(如机械臂的位置和夹爪的开合状况)。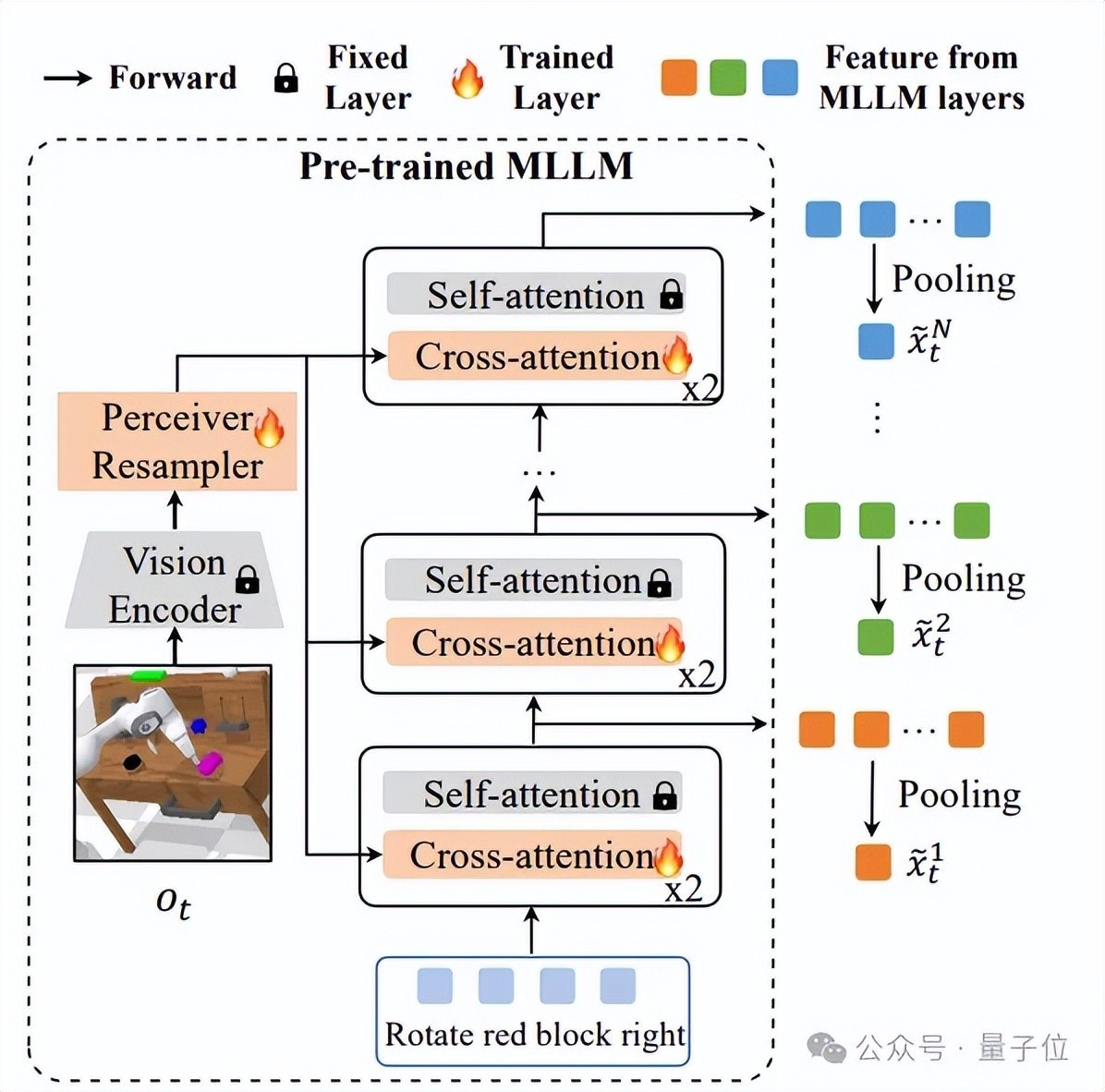
DeeR-VLA使用了一种特有的动作一致性准则来决定是否提前退出。
通过对比相邻出口的动作展望收尾,若收尾相反小于阈值,则揣度模子照旧达到不休状况,无需进一步盘算推算。
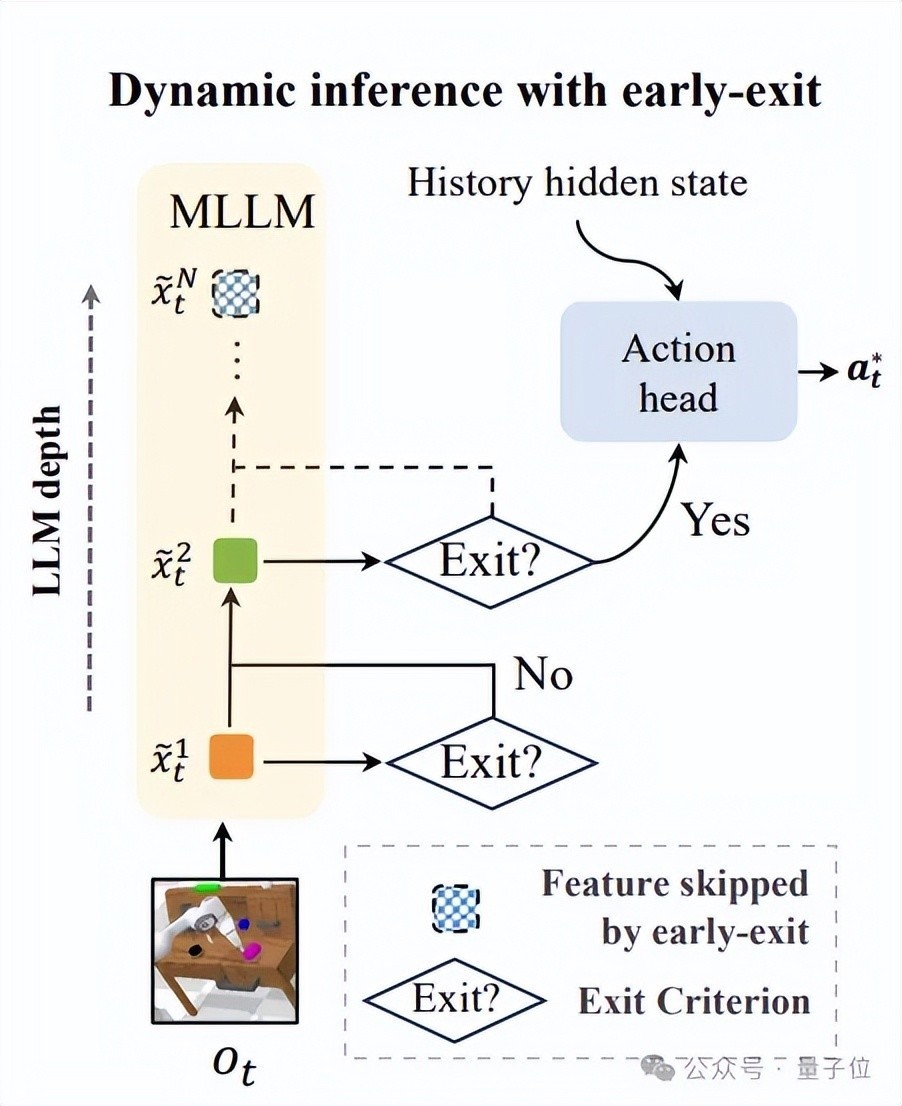
动作一致性的阈值无需手动成立,模子不错自动盘算推算出合适的阈值来满足给定的设定平均盘算推算资本、峰值盘算推算、显存预算,动态调整盘算推算范畴,以恰当不同的硬件环境和及时性需求。
为了自动寻找最好退出阈值,DeeR-VLA还引入了贝叶斯优化面容。在稽察或实质利用中,该面容通过探索和响应持续微调退出计谋,确保盘算推算资源的最优分拨。

在DeeR-VLA中,动态推理时,模子凭证详情味的标准在每个期间步聘任合适的出口,并收集时序上每一个时刻的特征生成最终的展望。
关联词,在稽察阶段,由于穷乏明确的肃除标准,模子并不明晰时序上出口特征的分散,这导致稽察时的行动与推理时有所不同。
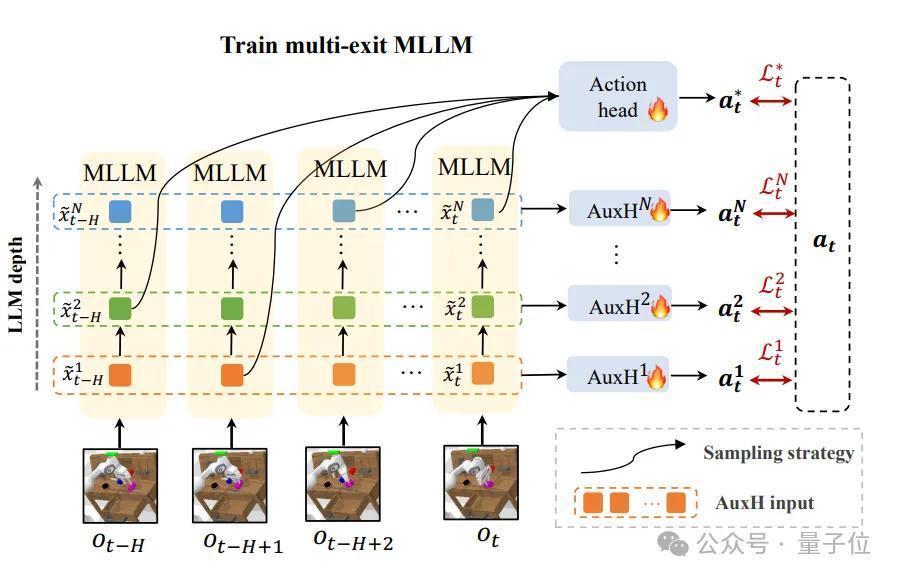
为了处治这一问题,DeeR-VLA引入了立时出口采样计谋。
在稽察进程中,模子在每个期间步立时聘任一个出口进行盘算推算,这么不错确保模子在通盘出口序列上齐能进行灵验学习,并生成高质料的展望。
这种计谋灵验减少了稽察和推理之间的分散相反,使得模子大约更好地粗疏动态推理进程中的概略情味。
此外,论文作家还引入了援手展望头(Auxiliary Heads)动作独特的监督信号,对每个出口的特征进行优化,使其更得当于动作展望任务。
实践考据
DeeR-VLA框架在CALVIN长Horizon多任务话语截至挑战(LH-MTLC)基准上进行评估。该基准倡导是测试机器东说念主在天然话语教唆下引申任务序列的智商,其中每个任务序列包含五个子任务。
由于多模态大模子中LLM部分占据主要的参数目,DeeR-VLA主要诊治LLM部分的盘算推算量和显存占用,而不是全体框架的从简。
通过在不同环境成立下的测试,DeeR-VLA展现了出色的发扬,尤其是在职务生效能与盘算推算后果之间的均衡。
与其他SOTA面容比拟,DeeR-VLA在职务生效能上保持竞争力的同期,LLM部分的盘算推算资源顿然大幅减少。
举例,在D→D成立下,DeeR-VLA以更少的盘算推算量(5.9倍减少的FLOPs)和2倍更低的GPU内存顿然,依然达到了RoboFlamingo++的性能。

为了考据DeeR-VLA在实质推理中的后果,盘问团队在Nvidia V100 GPU上对DeeR和RoboFlamingo++进行了比较。
收尾标明,DeeR-VLA的LLM部分的推理期间比RoboFlamingo++减少了68.1%,且两者在职务生效能上险些交流。
这一实考据明了DeeR-VLA框架不仅在表面上大约减少盘算推算背负,何况在实质利用中也能权贵普及推理速率。
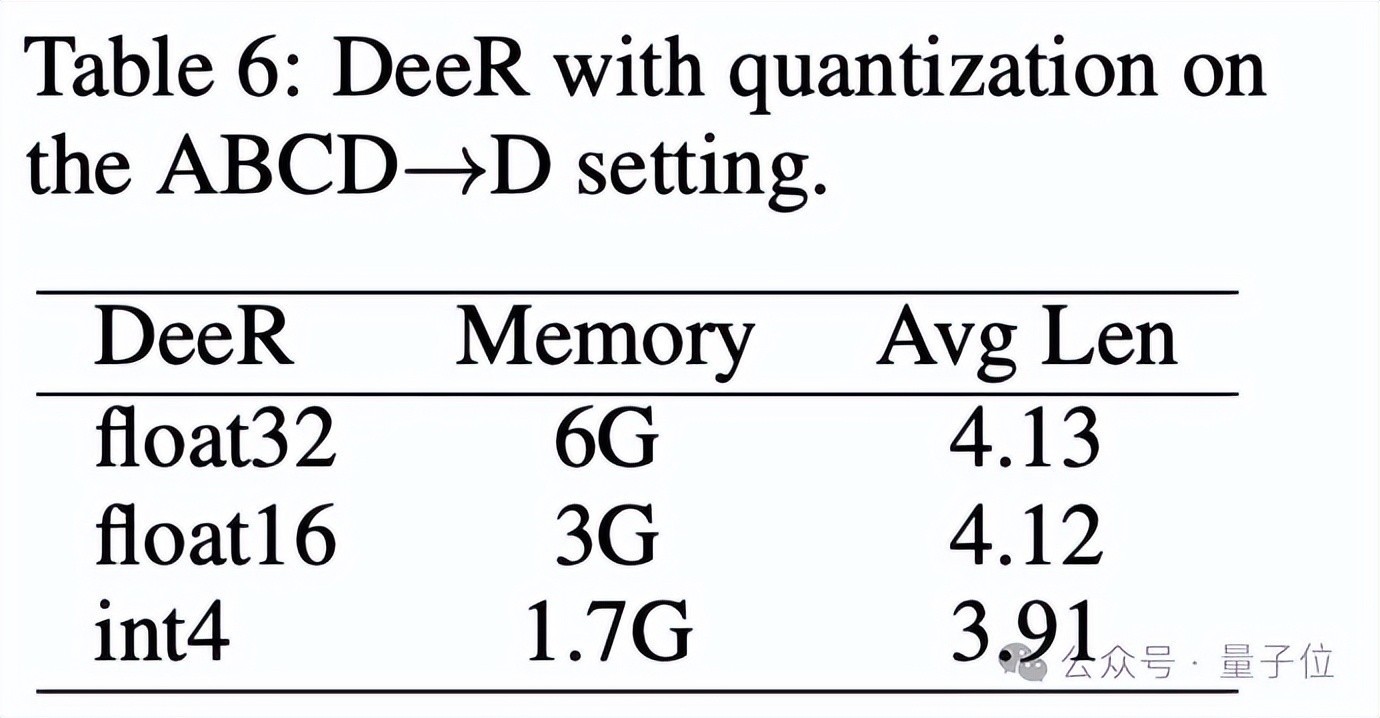
同期,DeeR-VLA框架大约与量化本事相结合,进一步减少模子LLM部分的内存使用。
论文作家先容
该论文的一作是清华大学自动化系三年事博士生Yue Yang,他专注于强化学习、宇宙模子、多模态大模子和具身智能的盘问。
此前他动作中枢作家的论文《How Far is Video Generation from World Model: A Physical Law Perspective》被国表里繁多大佬Yan Lecun,xie saining,Kevin Murphy等转发。
另一位一作王语霖相同是清华大学的博士生。两位作家的导师齐是黄高。
论文作家主页:
https://yueyang130.github.io/论文勾搭:https://arxiv.org/abs/2411.02359v1代码和模子勾搭:https://github.com/yueyang130/DeeR-VLA— 完 —
量子位 QbitAI · 头条号签
诊治咱们91porn y,第一期间获知前沿科技动态约